Corpus-based learning analytics
Web app built for the Language & Technology Research Group at Teachers College, Columbia University.
I’m a part of the Language & Technology Research Group at Teachers College (TC), Columbia University, a growing group of curious people researching the impact of emerging technology, especially natural language tech, on education. You can also see the trainings and workshops I developed for the group here.
Context
Each year, the Community Language Program (CLP) at TC serves hundreds of adult English learners in NYC and visiting scholars & professionals from all over the world. It is also a “language lab” for TC’s professors & graduate students in linguistics and pedagogy research. Researchers and instructors need a tailored, accessible, and efficient system for longitudinal analysis of the massive language output and learner-instructor interactions in CLP.
Design highlights
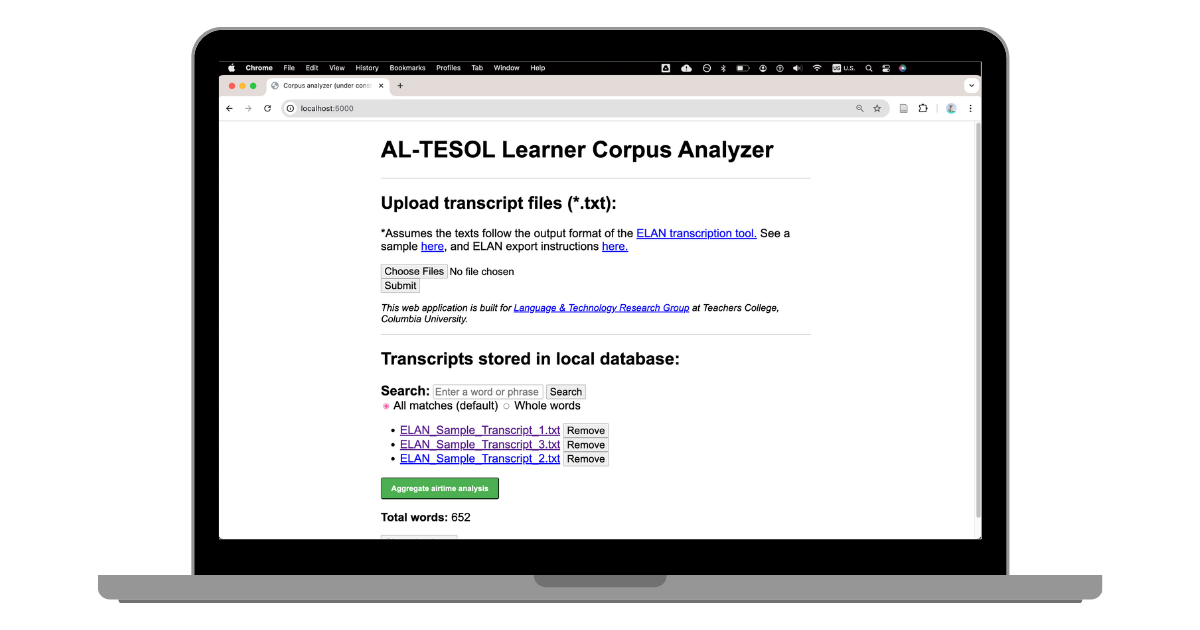
- A web application with an intuitive interface and zero demand for users to write code.
- Streamlines with CLP transcription data generated by human and AI annotators.
- Built-in database supports unlimited uploading, parsing, storing, and deleting of transcriptions.
- Core features include word queries, visual airtime breakdown (per class and overall), and speaker filtering.
- Modular design allows for easy integration of additional features.
Tools
Python, Flask, HTML/CSS, SQL, Regex, Visual Studio Code, Git, ChatGPT as pair programmer.
Role
I developed the project independently, while continuously integrating feedback from research group members to ensure the project met collective goals. I was responsible for the conceptualization, architecture, database schema, user interface & experience design, development, testing, and documentation of the project.
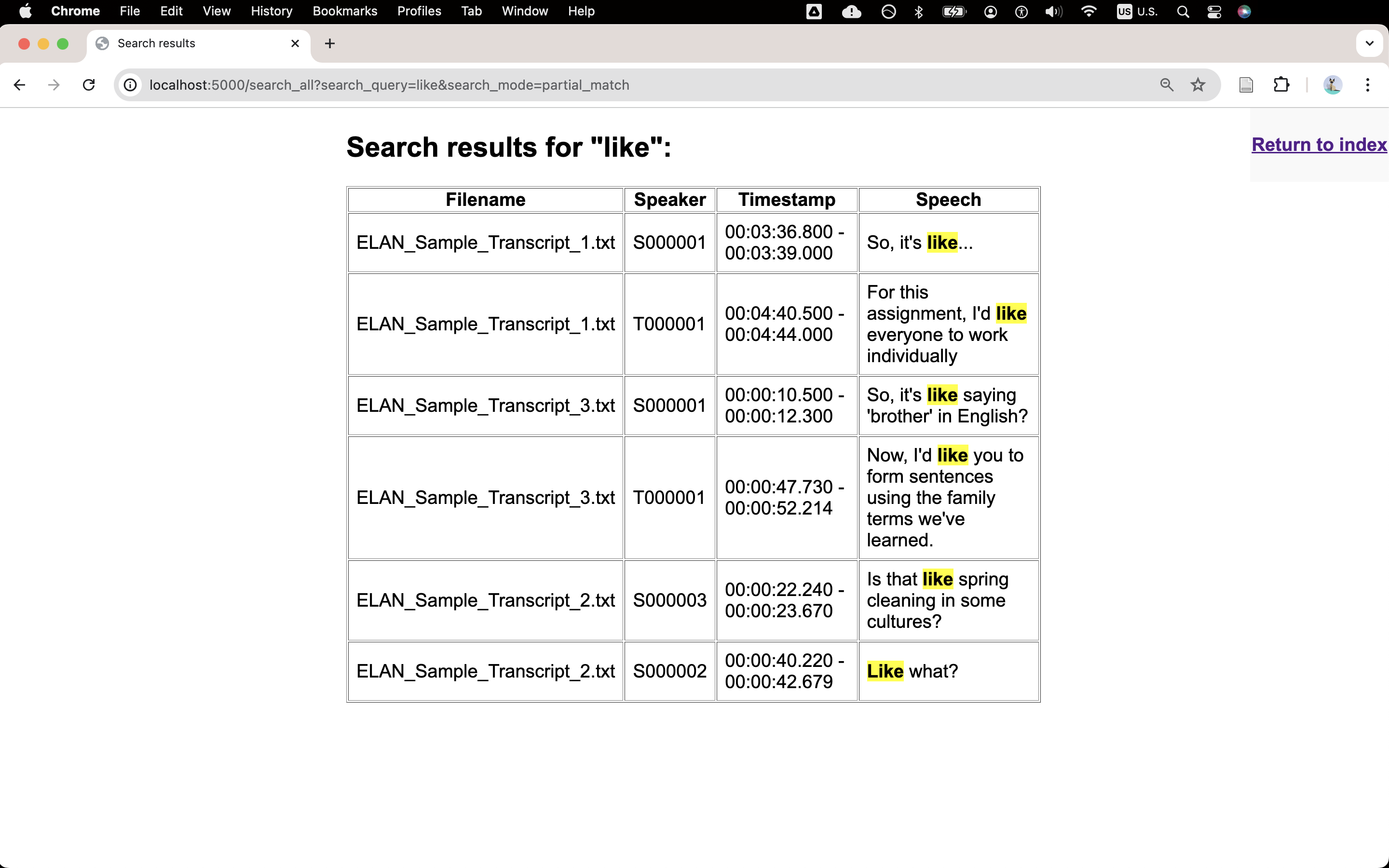 Screenshot of the search function.
Screenshot of the search function.
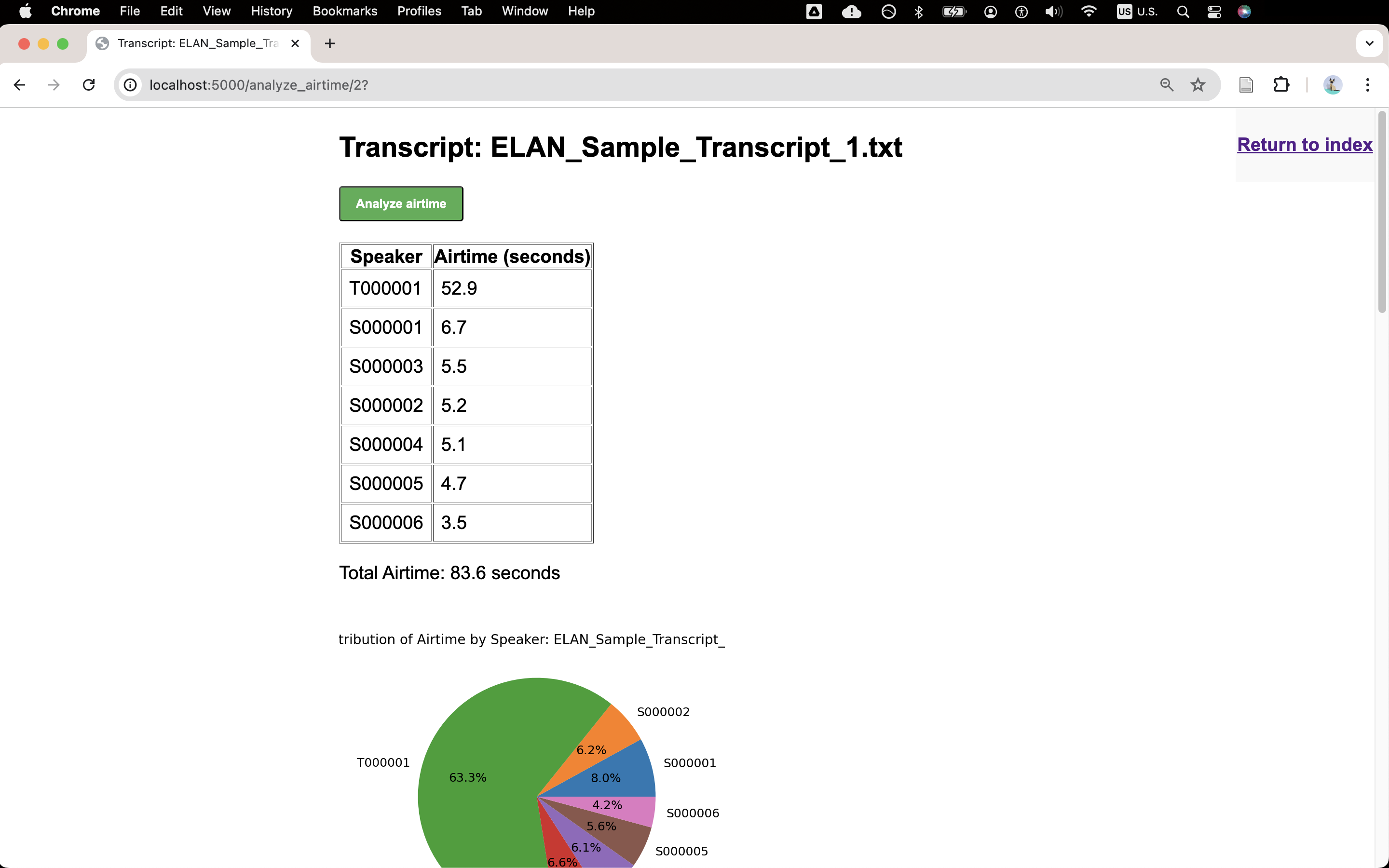 Screenshot of the airtime analysis function.
Screenshot of the airtime analysis function.
This project is undergoing iterative development. Contact me if you have any ideas or questions.